使用Linux管道来编排命令行实用程序如何协作。通过利用一组独立的命令并将它们转变为一个专心致志的团队,简化复杂的流程并提高您的工作效率。我们教你怎么做。
到处都是管道
管道是Linux和类Unix操作系统拥有的最有用的命令行功能之一。管道有无数种用途。看看任何Linux命令行文章-在任何网站上,而不仅仅是在我们的网站上-你会发现管道经常出现。我回顾了一些How-to Geek的Linux文章,所有文章都以某种方式使用了管道。
Linux管道允许您执行外壳不支持的开箱即用的操作。但是,因为Linux的设计理念是让许多小实用程序很好地执行它们的专用功能,并且没有不必要的功能-“做一件事,做好它”这句口头禅-您可以将命令字符串与管道结合在一起,以便一个命令的输出成为另一个命令的输入。你输入的每一个命令都会给团队带来独特的天赋,很快你就会发现你已经组建了一支胜利的队伍。
一个简单的例子
假设我们有一个目录,其中充满了许多不同类型的文件。我们想知道该目录中有多少特定类型的文件。还有其他方法可以做到这一点,但是本练习的目的是引入管道,所以我们将使用管道来完成。
我们可以使用ls轻松获得文件列表:
ls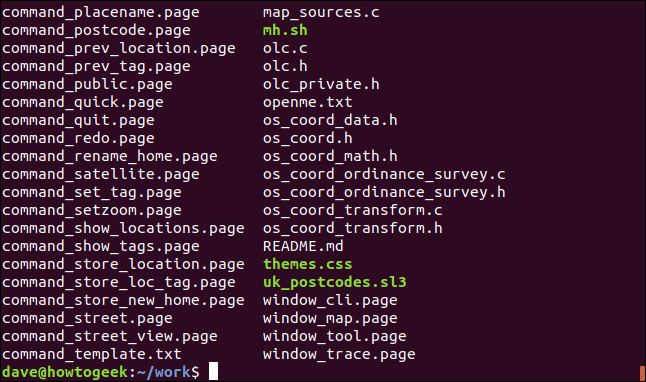
为了分离出感兴趣的文件类型,我们将使用grep。我们要查找文件名或文件扩展名中包含单词“page”的文件。
我们将使用shell特殊字符“|”将ls的输出通过管道传输到grep。
ls | grep "page"
grep打印与其搜索模式匹配的行。因此,这将为我们提供一个仅包含“.page”文件的列表。
即使是这个微不足道的示例也显示了管道的功能。%ls的输出未发送到终端窗口。它作为数据发送到grep,供grep命令使用。我们看到的输出来自grep,这是该链中的最后一个命令。
延伸我们的链条
让我们开始扩展我们的管道命令链。我们可以通过添加wc命令来计算“.page”文件的数量。我们将对wc使用-l(行数)选项。注意,我们还向ls添加了-l(长格式)选项。我们很快就会用到这个。
ls - | grep "page" | wc -l
grep不再是链中的最后一个命令,因此我们看不到它的输出。grep的输出被送入wc命令。我们在终端窗口中看到的输出来自wc。WC报告目录中有69个“.page”文件。
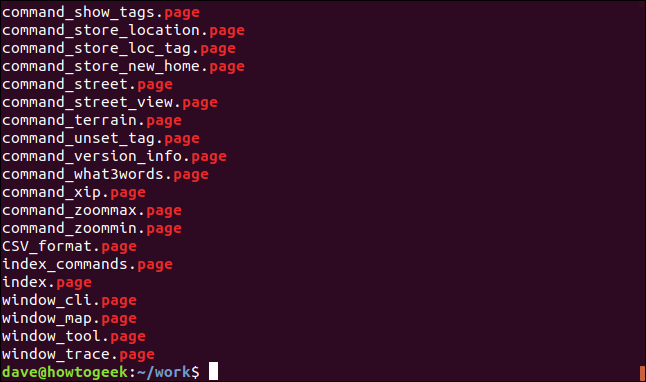
让我们再延长一次。我们将从命令行中删除wc命令,并将其替换为wawk。使用-l(长格式)选项时,ls的输出中有9列。我们将使用awk打印第5、3和9列。这些是文件的大小、所有者和名称。
ls -l | grep "page" | awk '{print $5 " " $3 " " $9}'
对于每个匹配的文件,我们都会获得这些列的列表。
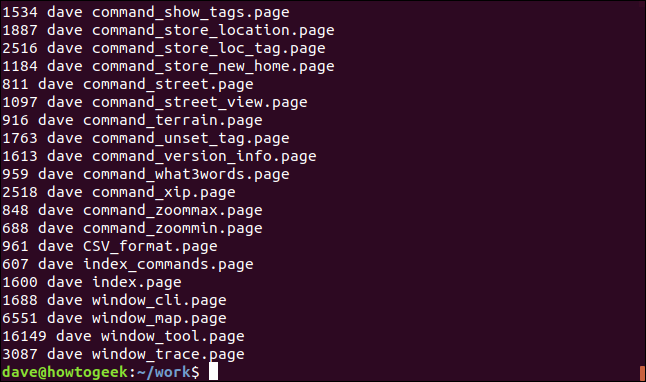
现在,我们将通过SORT命令传递该输出。我们将使用-n(数字)选项让Sort知道第一列应该被视为数字。
ls -l | grep "page" | awk '{print $5 " " $3 " " $9}' | sort -n
输出现在按文件大小顺序排序,我们自定义选择了三列。
添加另一个命令
我们将通过添加Tail命令来结束。我们将告诉它只列出最后五行输出。
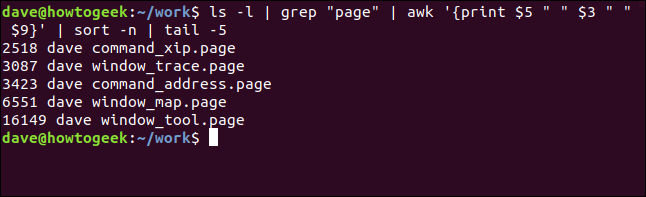
ls -l | grep "page" | awk '{print $5 " " $3 " " $9}' | sort -n | tail -5
这意味着我们的命令转换为类似于“显示此目录中的五个最大的”.page“文件,按大小排序。”当然,没有命令来实现这一点,但是通过使用管道,我们已经创建了自己的管道。我们可以将此命令或任何其他长命令添加为别名或shell函数,以节省所有键入。
以下是输出:
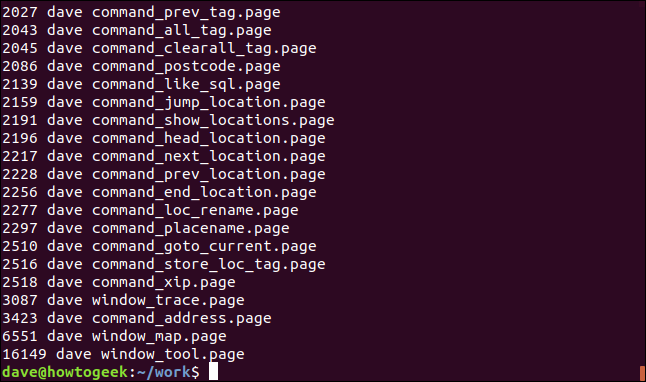
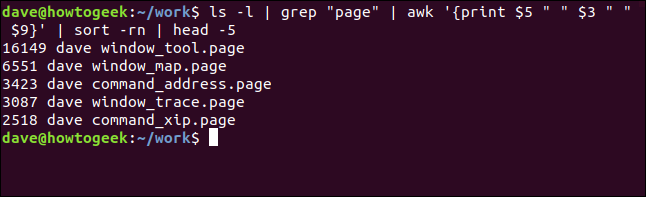
我们可以颠倒大小顺序,方法是向排序命令添加-r(反转)选项,并使用HEAD而不是TABLE从输出的顶部选取行。
这次列出的五个最大的“.page”文件从大到小:
最近的一些例子
这里有两个有趣的例子,摘自最近的How-to极客文章。
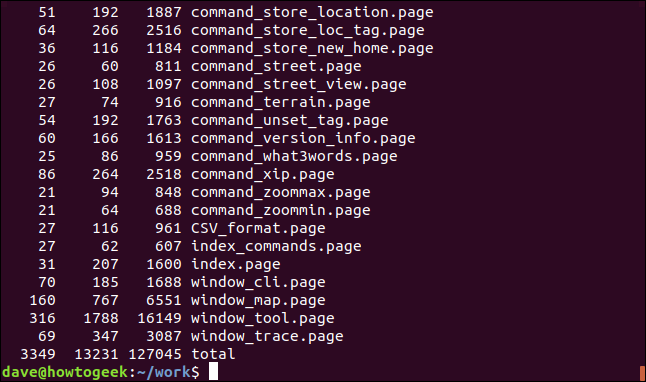
一些命令(如xargs命令)被设计为通过管道将输入输送到它们。下面是一种让wc计算多个文件中的单词、字符和行的方法,方法是将ls输送到xargs,xargs然后将文件名列表提供给wc,就像它们已作为命令行参数传递给wc一样。
ls *.page | xargs wc
单词、字符和行的总数列在终端窗口的底部。
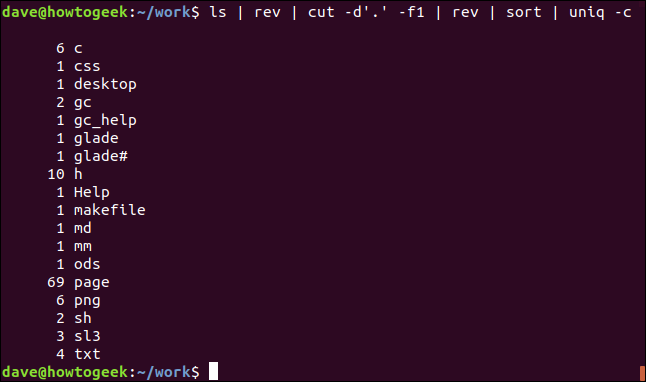
下面是一种获取当前目录中唯一文件扩展名的排序列表的方法,其中包含每种类型的计数。
ls | rev | cut -d'.' -f1 | rev | sort | uniq -c
这里发生了很多事情。
ls:列出目录中的文件。 rev:反转文件名中的文本。 Cut:在指定分隔符“.”的第一个匹配处剪切字符串。此之后的文本将被丢弃。 rev:反转剩余的文本,即文件扩展名。 排序:按字母顺序对列表进行排序。 uniq:统计列表中每个唯一条目的数量。
输出显示文件扩展名列表,按字母顺序排序,并包含每种唯一类型的计数。
命名管道
我们还可以使用另一种类型的管道,称为命名管道。前面示例中的管道是由shell在处理命令行时动态创建的。管道被创建、使用,然后被丢弃。他们是短暂的,没有留下任何他们自己的痕迹。只有在使用它们的命令运行时,它们才会存在。
命名管道在文件系统中显示为持久对象,因此您可以使用ls查看它们。它们之所以持久,是因为它们可以在计算机重新启动后存活下来--尽管那时它们中的任何未读数据都将被丢弃。
命名管道一次使用了很多,以允许不同的进程发送和接收数据,但我很久没有看到它们这样使用了。毫无疑问,仍有一些人在使用它们,效果很好,但我最近没有遇到任何人。但是出于完整性的考虑,或者只是为了满足您的好奇心,下面是您可以如何使用它们。
命名管道是使用mkfio命令创建的。该命令将在当前目录中创建一个名为“geek-Pipe”的命名管道。
mkfifo geek-pipe
如果使用带有-l(长格式)选项的ls命令,我们可以看到命名管道的详细信息:
ls -l geek-pipe
清单的第一个字符是“p”,表示它是一个管道。如果是“d”,则表示文件系统对象是目录,破折号“-”表示它是常规文件。
使用命名管道
我们用我们的烟斗吧。我们在前面的示例中使用的未命名管道将数据立即从发送命令传递到接收命令。通过命名管道发送的数据将保留在管道中,直到被读取。数据实际上保存在内存中,因此命名管道的大小在ls清单中不会改变,无论其中是否有数据。
在本例中,我们将使用两个终端窗口。我将使用标签:
# Terminal-1在一个终端窗口中
# Terminal-2在另一种情况下,所以你可以区分它们。散列“#”告诉shell后面的是注释,并忽略它。
让我们将上一个示例的全部内容重定向到命名管道中。因此,我们在一个命令中同时使用未命名管道和命名管道:
ls | rev | cut -d'.' -f1 | rev | sort | uniq -c > geek-pipe
看起来不会有太多事情发生。您可能会注意到,您没有返回到命令提示符,所以发生了一些事情。
在另一个终端窗口中,发出以下命令:
cat < geek-pipe
我们将命名管道的内容重定向到cat中,以便cat在第二个终端窗口中显示该内容。以下是输出:
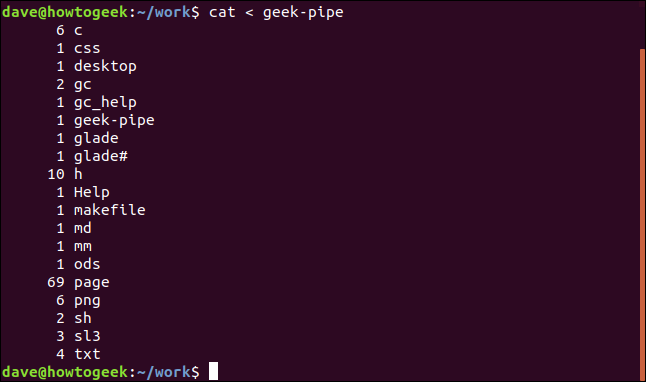
您将看到您已返回到第一个终端窗口中的命令提示符。

那么,刚才发生的事。
我们将一些输出重定向到命名管道。 第一个终端窗口未返回命令提示符。 数据将一直保留在管道中,直到从第二个终端的管道中读取。 我们返回到第一个终端窗口中的命令提示符。
您可能认为可以在第一个终端窗口中将命令作为后台任务运行,方法是在命令末尾添加一个&。你说得对。在这种情况下,我们将立即返回到命令提示符。
不使用后台处理的目的是强调命名管道是阻塞进程。将某些内容放入命名管道中只能打开管道的一端。在读取程序提取数据之前,另一端不会打开。内核会暂停第一个终端窗口中的进程,直到从管道的另一端读取数据。
管道的力量
如今,命名管道是一种新奇的行为。
另一方面,普通的老式Linux管道是您的终端窗口工具包中可以使用的最有用的工具之一。Linux命令行开始活跃起来,当您能够编排一组命令以产生一个连贯的性能时,您将获得一种全新的动力。
分离提示:最好通过一次添加一个命令并使该部分正常工作,然后通过管道输入下一个命令来编写管道命令。