Linux uniq命令在您的文本文件中快速查找唯一或重复的行。在本指南中,我们将介绍它的多功能性和特性,以及如何最大限度地利用这个漂亮的实用程序。
在Linux上查找匹配的文本行
uniq命令快速、灵活,并且非常擅长它所做的事情。然而,与许多Linux命令一样,它也有一些怪癖-只要您了解它们,这就很好。如果你在没有一点内幕知识的情况下冒险,你很可能会对结果感到挠头。我们会边走边指出这些怪癖。
uniq命令非常适合那些一心一意、只想做一件事、做好一件事的人。这就是为什么它也特别适合与管道一起工作,并在指挥管道中发挥其作用。它最频繁的合作者之一是Sort,因为Uniq必须对要处理的输入进行排序。
让我们点燃它吧!
相关:如何在Linux上使用管道
在不带选项的情况下运行uniq
我们有一个文本文件,其中包含罗伯特·约翰逊的歌曲“我相信我会把扫帚上的灰尘”的歌词。让我们看看Uniq是如何看待它的。
我们将键入以下内容以通过管道将输出转换为LESS:
uniq ust-my-broom.txt|更少

我们用更少的篇幅得到整首歌,包括重复的台词:
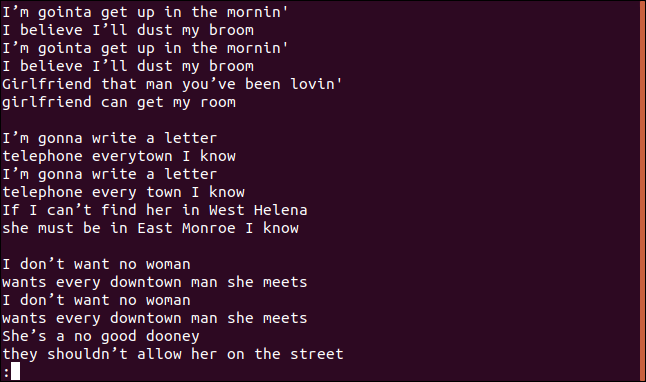
这似乎既不是独一无二的线,也不是重复的线。
对-因为这是第一个怪癖。如果不带选项运行uniq,它的行为就像使用了-u(唯一行)选项一样。这告诉Uniq只打印文件中的唯一行。您看到重复行的原因是,对于Uniq而言,要将某行视为重复行,它必须与其重复行相邻,而这正是SORT的用武之地。
当我们对文件进行排序时,它会对重复行进行分组,而uniq会将它们视为重复行。我们将对文件使用SORT,将排序后的输出通过管道传输到uniq,然后通过管道将最终输出传输到LESS。
为此,我们键入以下内容:
排序灰尘-my-broom.txt|uniq|更少

排序后的行列表将显示在LESS中。
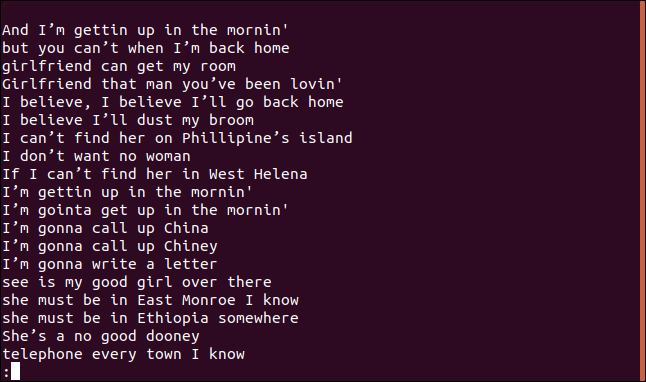
“我相信我会除掉扫帚上的灰尘”这句话肯定不止一次出现在这首歌中。事实上,在这首歌的前四行里重复了两次。
那么,为什么它会出现在一系列独特的行中呢?因为一行第一次出现在文件中时,它是唯一的;只有后续条目是重复的。您可以将其视为列出每个唯一行的第一个匹配项。
让我们再次使用排序,并将输出重定向到一个新文件。这样,我们就不必在每个命令中都使用排序。
我们键入以下命令:
sorted.txt>sorted.txt

现在,我们有一个预先分类的文件可以使用。
计数重复项
您可以使用-c(计数)选项打印每行在文件中出现的次数。
键入以下命令:
uniq-c sorted.txt|更少

每行以该行在文件中出现的次数开始。但是,您会注意到第一行是空的。这会告诉您文件中有五个空行。
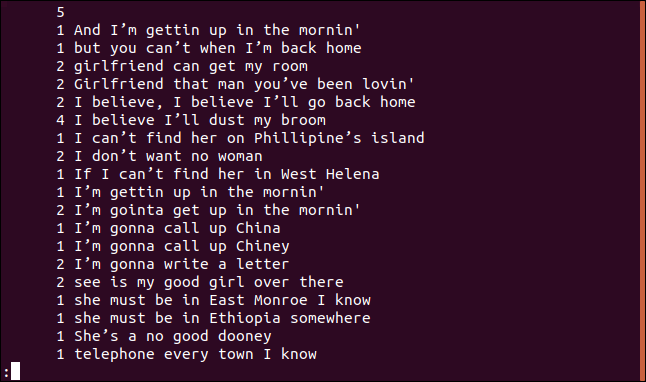
如果想要按数字顺序对输出进行排序,可以将来自uniq的输出输入到排序中。在我们的示例中,我们将使用-r(反转)和t-n(数字排序)选项,并通过管道将结果传递给LESS。
我们键入以下内容:
uniq-c排序.txt|排序-rn|更少

该列表根据每行出现的频率按降序排序。

仅列出重复行
如果只想查看文件中重复的行,可以使用-d(重复)选项。无论一行在文件中重复多少次,它都只列出一次。
要使用此选项,我们键入以下内容:
uniq-d排序.txt

为我们列出了重复的行。您将注意到顶部的空行,这意味着文件包含重复的空行-这不是uniq留下的用于美化清单的空格。
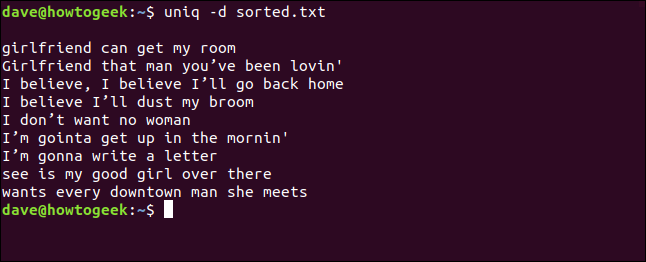
我们还可以组合-d(重复)和-c(计数)选项,并通过SORT传输输出。这为我们提供了至少出现两次的行的排序列表。
键入以下内容以使用此选项:
uniq-d-c sorted.txt|排序-rn
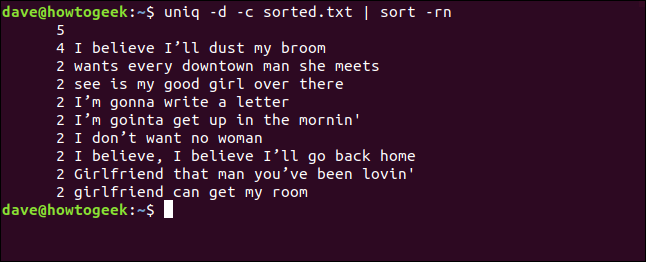
列出所有重复行
如果要查看每个重复行的列表,以及文件中每次出现一行时的条目,可以使用-D(所有重复行)选项。
要使用此选项,请键入以下内容:
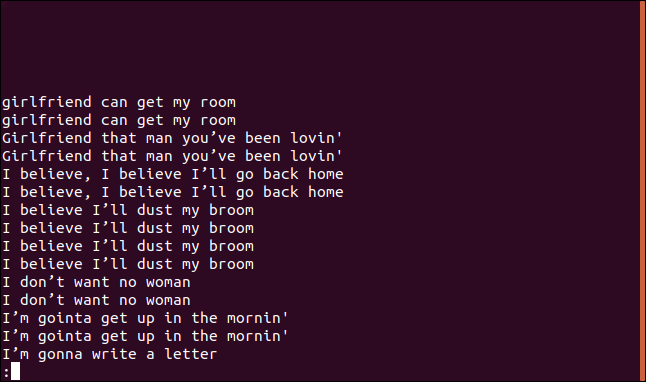
Uniq-D排序.txt|更少

该列表包含每个重复行的条目。
如果使用--group选项,它将打印每个重复的行,并在每个组之前(前置)或之后(追加),或在每个组前后(两者)都打印一个空行。
我们使用Append作为修饰符,因此我们键入以下内容:
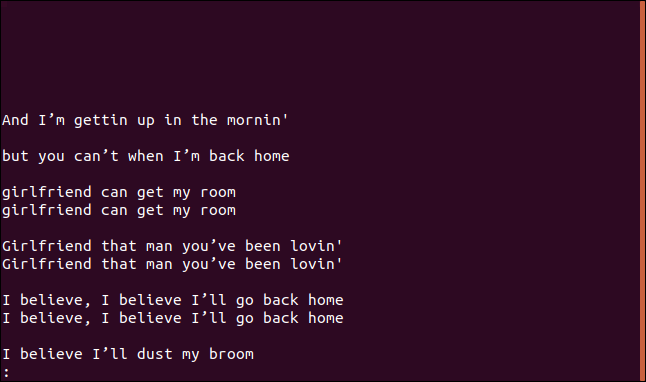
uniq--group=追加排序.txt|更少

这些组之间用空行分隔,以便于阅读。
检查一定数量的字符
默认情况下,uniq检查每行的整个长度。但是,如果要将检查限制在一定数量的字符内,则可以使用-w(检查字符)选项。
在本例中,我们将重复最后一个命令,但将比较限制在前三个字符。为此,我们键入以下命令:
uniq-w 3--group=append sorted.txt|less

我们收到的结果和分组非常不同。
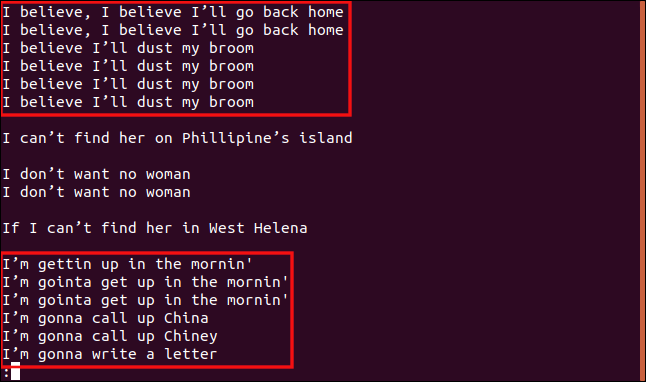
所有以“i b”开头的行都被分组在一起,因为这些行的那些部分是相同的,因此它们被认为是重复的。
同样,所有以“I‘m”开头的行都被视为重复行,即使文本的其余部分不同。
忽略一定数量的字符
在某些情况下,跳过每行开头的特定数量的字符可能是有益的,例如,当文件中的行标有编号时。或者,假设您需要uniq跳过时间戳,并从第六个字符开始检查行,而不是从第一个字符开始。
下面是我们的排序文件的一个版本,带有编号的行。
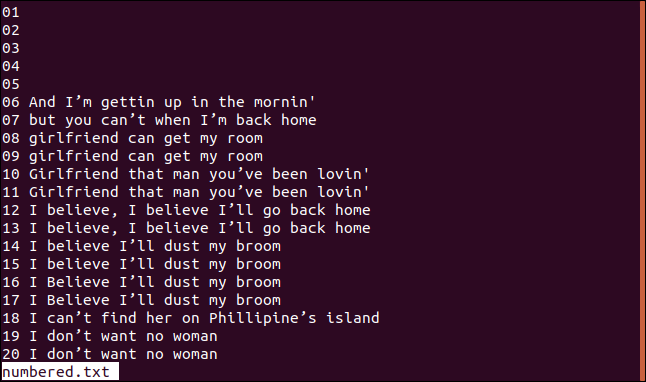
如果我们希望Uniq从第三个字符开始比较检查,我们可以通过键入以下内容使用-s(跳过字符)选项:
uniq-s 3-d-c编号.txt
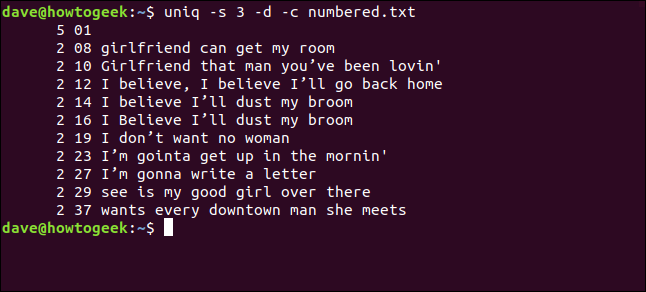
这些行被检测为重复行,并被正确计数。请注意,显示的行号是每个副本第一次出现的行号。
您也可以跳过字段(一串字符和一些空格)而不是字符。我们将使用-f(字段)选项来告诉Uniq忽略哪些字段。
我们键入以下命令来告诉uniq忽略第一个字段:
uniq-f 1-d-c编号为.txt
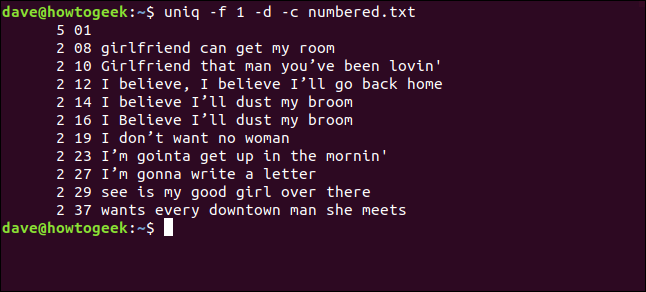
我们得到的结果与我们告诉Uniq在每行开头跳过三个字符时得到的结果相同。
忽略案例
默认情况下,Uniq区分大小写。如果相同的字母显示为大写和小写,Uniq会认为这些行是不同的。
例如,检查以下命令的输出:
uniq-d-c sorted.txt|排序-rn
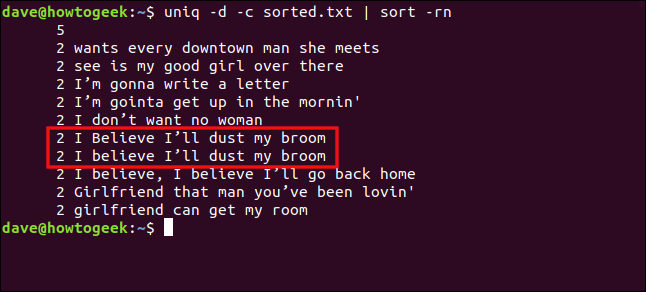
“我相信我会除掉扫帚上的灰尘”和“我相信我会除掉扫帚上的灰尘”这两句话不会被视为重复的,因为“Believe”中“B”的大小写不同。
但是,如果我们包括-i(忽略大小写)选项,这些行将被视为重复行。我们键入以下内容:
uniq-d-c-i sorted.txt|排序-rn
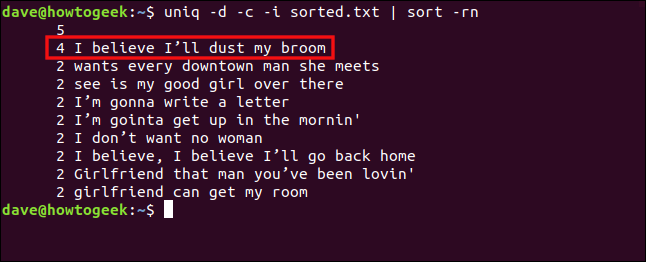
现在,这些行被视为重复行并分组在一起。
Linux提供了大量特殊的实用程序供您使用。和他们中的许多人一样,uniq不是您每天都会使用的工具。
这就是为什么精通Linux的很大一部分原因是记住哪个工具可以解决您当前的问题,以及在哪里可以再次找到它。不过,如果你练习一下,你就会顺利上路。
或者,你可以随时搜索How-to Geek-我们可能有一篇关于它的文章。