Linux curl命令可以做的不仅仅是下载文件。找出curl的功能,以及何时应该使用它而不是wget。
卷发VS WGET:有什么不同?
人们常常很难确定wget和curl命令的相对优势。这些命令确实有一些功能重叠。他们每个人都可以从远程位置检索文件,但相似之处仅此而已。
Wget是下载内容和文件的绝佳工具。它可以下载文件、网页和目录。它包含遍历网页中的链接并递归下载整个网站内容的智能例程。作为命令行下载管理器,它是无与伦比的。
CURL满足了完全不同的需求。是的,它可以检索文件,但不能递归导航网站查找要检索的内容。cURL实际上所做的是让您通过向远程系统发出请求,并检索和显示它们的响应来与远程系统交互。这些响应很可能是网页内容和文件,但它们也可以包含由于cURL请求提出的“问题”而通过Web服务或API提供的数据。
而且cURL并不局限于网站。CURL支持20多种协议,包括HTTP、HTTPS、SCP、SFTP和FTP。而且可以说,由于其对Linux管道的卓越处理,cURL可以更容易地与其他命令和脚本集成。
curl的作者有一个网页,描述了他看到的curl和wget之间的区别。
安装卷曲
在用于研究本文的计算机中,Fedora 31和Manjaro 18.1.0已经安装了CURL。CURL必须安装在Ubuntu18.04LTS上。在Ubuntu上,运行以下命令进行安装:
sudo apt-get install curl
卷发版
version选项使curlreport报告其版本。它还列出了它支持的所有协议。
curl --version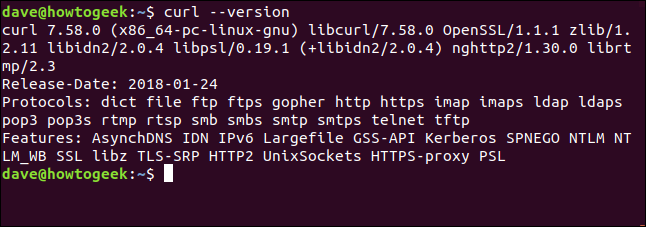
检索网页
如果我们将curl指向网页,它将为我们检索该网页。
curl https://www.bbc.com
但它的默认操作是将其作为源代码转储到终端窗口。
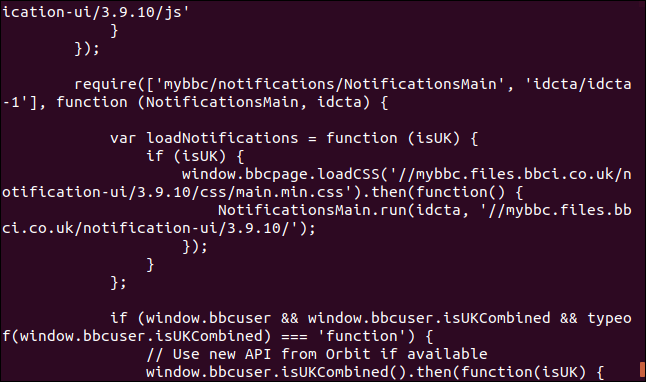
注意:如果您不告诉curl您希望将某些内容存储为文件,它总是会将其转储到终端窗口。如果它正在检索的文件是二进制文件,则结果可能是不可预测的。外壳程序可能会尝试将二进制文件中的一些字节值解释为控制字符或转义序列。
将数据保存到文件
让我们告诉cURL将输出重定向到一个文件中:
curl https://www.bbc.com > bbc.html
这一次我们没有看到检索到的信息,它被直接发送给我们的文件。因为没有终端窗口输出可供显示,所以cURL输出一组进度信息。
在前面的示例中它没有这样做,因为进度信息会分散在整个网页源代码中,所以curl自动将其取消。
在本例中,cURL检测到输出被重定向到文件,并且生成进度信息是安全的。
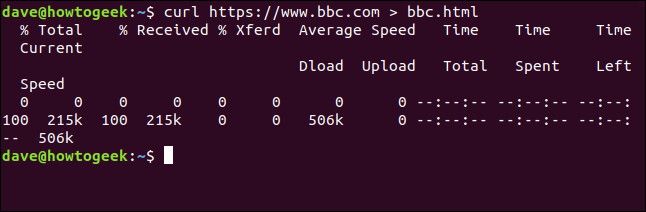
提供的资料如下:
%Total:要检索的总金额。 接收百分比:到目前为止检索到的数据的百分比和实际值。 %xferd:如果正在上载数据,则为发送百分比和实际发送百分比。 平均速度Dload:平均下载速度。 平均上传速度:平均上传速度。 总计时间:转接的估计总持续时间。 花费的时间:到目前为止,此传输所用的时间。 剩余时间:预计完成转账的剩余时间。 当前速度:此传输的当前传输速度。
因为我们将输出从curl重定向到一个文件,所以我们现在有一个名为“bbc.html”的文件。
双击该文件将打开默认浏览器,以便显示检索到的网页。
请注意,浏览器地址栏中的地址是此计算机上的本地文件,而不是远程网站。
我们不需要重定向输出来创建文件。我们可以通过使用-o(输出)选项并告诉cURL创建文件来创建文件。在这里,我们使用-o选项并提供我们想要创建的“bbc.html”文件的名称。
curl -o bbc.html https://www.bbc.com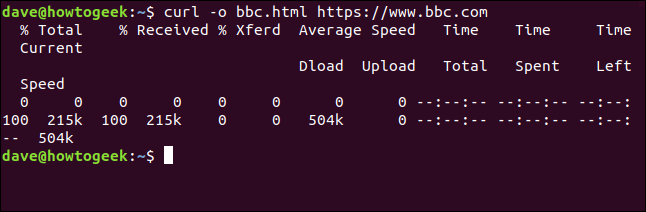
使用进度条监视下载
要将基于文本的下载信息替换为简单的进度条,请使用-#(进度条)选项。
curl -x -o bbc.html https://www.bbc.com
重新启动中断的下载
重新启动已终止或中断的下载很容易。让我们开始下载一个相当大的文件。我们将使用最新的长期支持版本Ubuntu18.04。我们使用--output选项指定要将其保存到的文件名:“ubuntu180403.iso”。
curl --output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso
下载开始,并以其接近完成的方式工作。
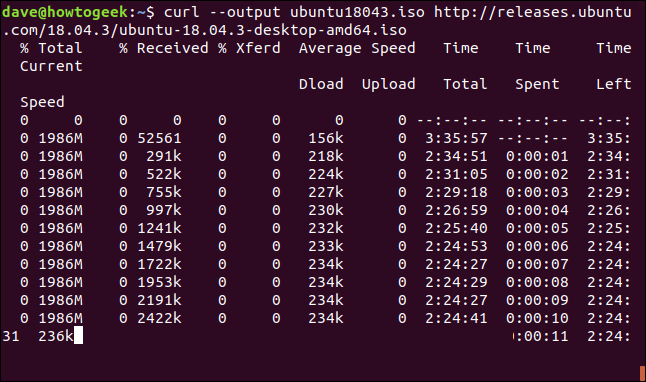
如果我们使用Ctrl+C强制中断下载,我们将返回命令提示符,并放弃下载。
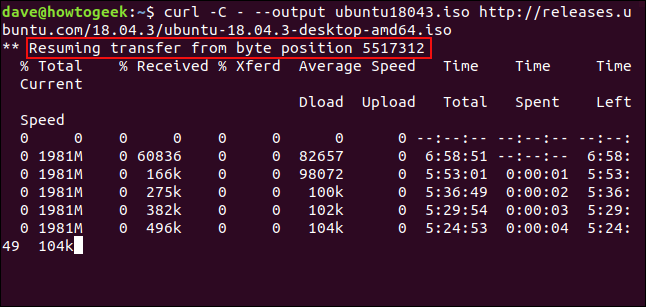
要重新启动下载,请使用-C(继续)选项。这会导致cURL在目标文件中的指定点或偏移量重新开始下载。如果使用连字符-作为偏移量,cURL将查看文件中已经下载的部分,并确定要为其自身使用的正确偏移量。
curl -C - --output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso
重新启动下载。CURL报告它重新启动时的偏移。
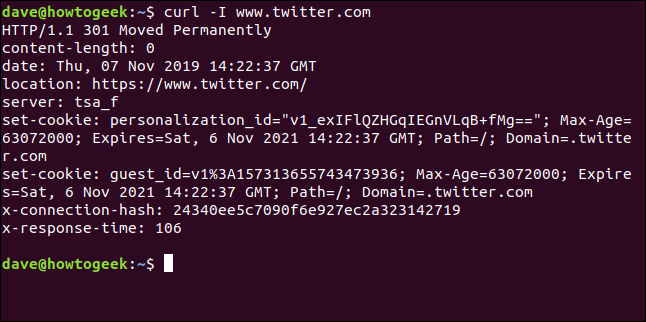
检索HTTP标头
使用-i(Head)选项,您只能检索HTTP标头。这与向Web服务器发送HTTP HEAD命令相同。
curl -I www.twitter.com
此命令仅检索信息,不下载任何网页或文件。
正在下载多个URL
使用xargs,我们可以一次下载多个URL。也许我们想下载一系列网页,这些网页组成了一篇文章或一篇教程。
将这些URL复制到编辑器并将其保存到名为“urls-to-download.txt”的文件中。我们可以使用xargs将文本文件每一行的内容作为参数处理,该参数将依次提供给curl。
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#0
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#1
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#2
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#3
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#4
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#5我们需要使用以下命令让xargs传递这些URL,以便一次卷曲一个:
xargs -n 1 curl -O < urls-to-download.txt请注意,此命令使用-O(远程文件)输出命令,该命令使用大写“O”。此选项会导致cURL使用与远程服务器上的文件同名的名称保存检索到的文件。
n 1选项告诉xargs将文本文件的每一行视为单个参数。
当您运行该命令时,您将看到多个下载一个接一个地开始和结束。
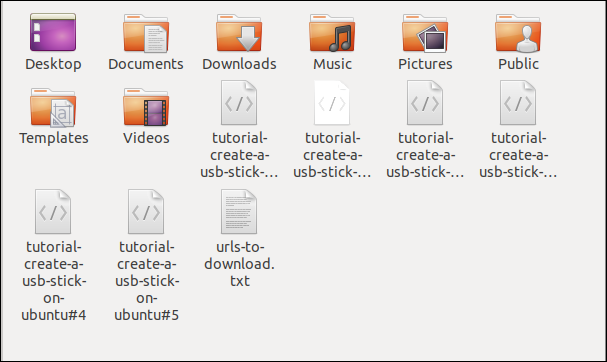
在文件浏览器中签入显示多个文件已下载。每个文件都带有它在远程服务器上的名称。
相关:如何在Linux上使用xargs命令
从FTP服务器下载文件
在文件传输协议(FTP)服务器上使用cURL很容易,即使您必须使用用户名和密码进行身份验证。要使用curl传递用户名和密码,请使用-u(用户)选项,然后键入用户名、冒号“:”和密码。不要在冒号前面或后面加空格。
这是Rebex托管的免费测试FTP服务器。测试FTP站点有一个预设的用户名“demo”,密码是“password”。不要在生产或“真正的”FTP服务器上使用这种弱用户名和密码。
curl -u demo:password ftp://test.rebex.net
cURL计算出我们将其指向FTP服务器,并返回服务器上存在的文件列表。

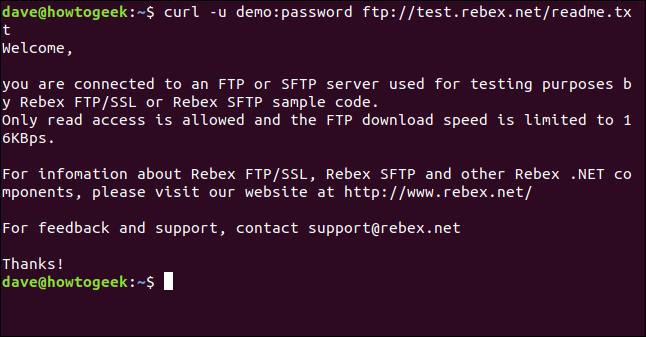
此服务器上唯一的文件是一个长度为403字节的“readme.txt”文件。让我们找回它吧。使用与刚才相同的命令,并附加文件名:
curl -u demo:password ftp://test.rebex.net/readme.txt
检索该文件,并且CURL在终端窗口中显示其内容。
在几乎所有情况下,将检索到的文件保存到磁盘上会比在终端窗口中显示更方便。同样,我们可以使用-O(远程文件)输出命令将文件保存到磁盘,其文件名与远程服务器上的文件名相同。
curl -O -u demo:password ftp://test.rebex.net/readme.txt
将检索该文件并将其保存到磁盘。我们可以使用ls检查文件详细信息。它与FTP服务器上的文件同名,长度相同,为403字节。
ls -hl readme.txt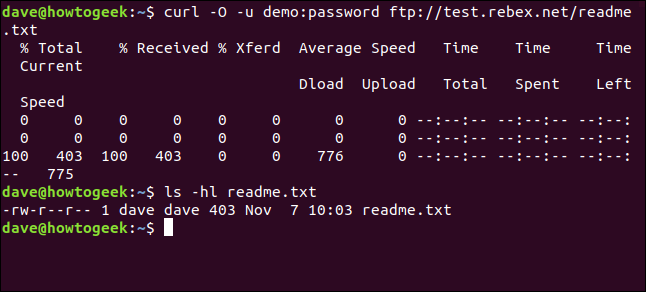
相关:如何在Linux上使用FTP命令
将参数发送到远程服务器
一些远程服务器将接受发送给它们的请求中的参数。例如,参数可以用来格式化返回的数据,或者它们可以用来选择用户希望检索的确切数据。通常可以使用CURL与网络应用编程接口(API)交互。
举个简单的例子,Iipify的网站有一个API可以被查询来确定你的外部IP地址。
curl https://api.ipify.org通过在命令中添加format参数,值为“json”的我们可以再次请求我们的外部IP地址,但这次返回的数据将以JSON格式编码。
curl https://api.ipify.org?format=json
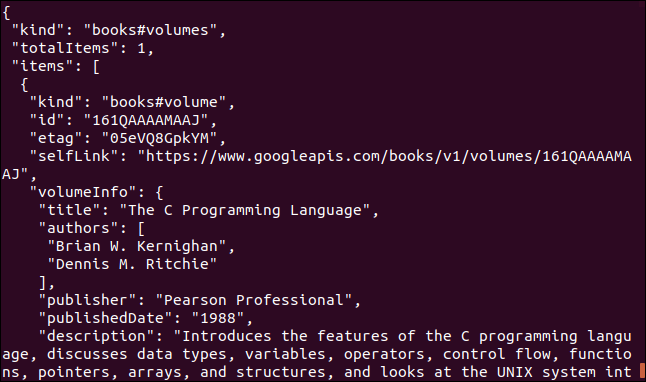
下面是使用Google API的另一个示例。它返回描述一本书的JSON对象。您必须提供的参数是图书的国际标准书号(ISBN)。你可以在大多数书的封底上找到这些,通常在条形码下面。我们在这里使用的参数是“0131103628”。
curl https://www.googleapis.com/books/v1/volumes?q=isbn:0131103628
返回的数据比较全面:
有时卷曲,有时发胖
如果我想从网站下载内容,并让网站的树形结构递归搜索该内容,我会使用wget。
如果我想与远程服务器或API交互,并可能下载一些文件或网页,我会使用cURL。特别是如果该协议是wget不支持的众多协议之一。