linux_stat命令显示的细节比ls多得多。使用这个信息丰富且可配置的实用程序,了解一下幕后情况。我们将向您演示如何使用它。
Stat会带你到幕后
ls命令很擅长它所做的事情-而且它做了很多事情-但是对于Linux,似乎总是有一种方法可以更深入地了解表面之下隐藏着什么。而且,通常情况下,这不仅仅是掀起地毯边缘的情况。你可以撕开地板,然后挖一个洞。你可以像剥洋葱一样剥开Linux的皮。
LS将向您显示有关文件的大量信息,如对其设置了哪些权限、大小以及它是文件还是符号链接。为了显示该信息,ls从称为inode的文件系统结构中读取该信息。
每个文件和目录都有一个索引节点。inode保存有关该文件的元数据,例如它占用哪些文件系统块,以及与该文件相关联的日期戳。inode就像文件的借书卡。但是ls只会向您展示部分信息。要查看所有内容,我们需要使用stat命令。
与ls一样,stat命令有很多选项。这使得它成为使用别名的一个很好的候选者。一旦您发现了一组特定的选项,可以使stat为您提供所需的输出,请将其包装在别名或shell函数中。这使得它的使用更加方便,而且您不必记住一组晦涩难懂的命令行选项。
相关:如何使用ls命令列出Linux上的文件和目录
快速比较
让我们使用ls为我们提供一个长清单(-l选项),其中包含人类可读的文件大小(-h选项):
ls -lh ana.h
从左到右,ls提供的信息是:
第一个字符是连字符“-”,这告诉我们该文件是常规文件,而不是套接字、符号链接或其他类型的对象。 所有者、组和其他权限以八进制格式列出。 指向此文件的硬链接数。在这种情况下,而且在大多数情况下,它将是一个。 文件所有者是戴夫。 群主是戴夫。 文件大小为802字节。 该文件最后一次修改是在2015年12月13日星期五。 文件名为ana.c。
让我们用STAT来看看:
stat ana.h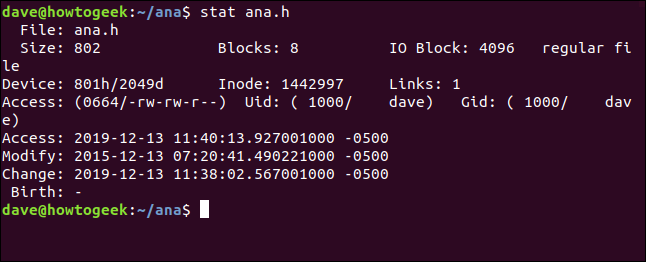
我们从STAT获得的信息是:
文件:文件的名称。通常,它与我们在命令行上传递给stat的名称相同,但如果我们查看的是符号链接,则可能会有所不同。 Size:文件的大小(以字节为单位)。 块:文件存储在硬盘上所需的文件系统块的数量。 IO块:文件系统块的大小。 文件类型:元数据描述的对象类型。最常见的类型是文件和目录,但也可以是链接、套接字或命名管道。 Device:十六进制和十进制的设备号。这是存储文件的硬盘的ID。 inode:inode编号。即此inode的ID号。信息节点编号和设备编号一起唯一标识文件。 链接:此数字指示有多少硬链接指向此文件。每个硬链接都有自己的索引节点。因此,考虑这个数字的另一种方式是有多少inode指向这一个文件。每次创建或删除硬链接时,此数字都会向上或向下调整。当它达到零时,文件本身已被删除,索引节点也被删除。如果对目录使用STAT,则此数字表示目录中的文件数,包括“。当前目录的条目和“..”父目录的条目。 访问:文件权限以其八进制和传统的rwx(读、写、执行格式)显示。 UID:所有者的用户ID和帐户名。 GID:所有者的组ID和帐户名。 Access:访问时间戳。并不像看起来那么直截了当。现代Linux发行版使用一种称为Relatime的方案,该方案试图优化更新访问时间所需的硬盘写入。简单地说,如果访问时间早于修改后的时间,则更新访问时间。 Modify:修改时间戳。这是上次修改文件内容的时间。(幸运的是,这个文件的内容最后一次更改是在四年前的今天。)。 Change:更改时间戳。这是上次更改文件属性或内容的时间。如果您通过设置新的文件权限来修改文件,则更改时间戳将会更新(因为文件属性已更改),但修改后的时间戳不会更新(因为文件内容未更改)。 出生日期:保留为显示文件的原始创建日期,但在Linux中未实现。
了解时间戳
时间戳是时区敏感的。*每行末尾的-0500表示此文件是在协调世界时(UTC)时区的计算机上创建的,该时区比当前计算机的时区早5小时。因此,这台计算机比创建此文件的计算机晚了5个小时。事实上,该文件是在一台英国时区计算机上创建的,我们现在在美国东部标准时区的一台计算机上查看它。
MODIFY和CHANGE时间戳可能会造成混淆,因为对于外行来说,它们的名字听起来好像意思是一样的。
让我们使用chmod修改名为ana.c的文件的文件权限。我们将使它对每个人都可写。这不会影响文件的内容,但会影响文件的属性。
chmod +w ana.c然后我们将使用stat查看时间戳:
stat ana.c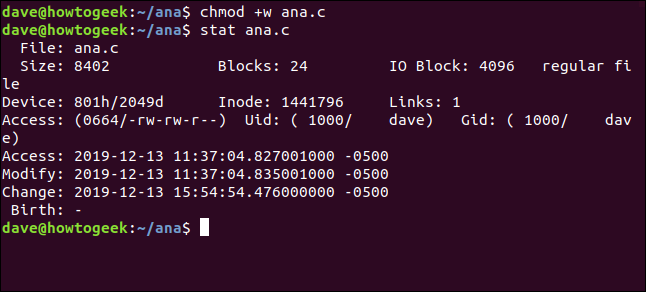
更改时间戳已更新,但修改后的时间戳尚未更新。
修改后的时间戳仅在文件内容更改时才会更新。内容更改和属性更改都会更新更改时间戳。
对多个文件使用Stat
要让stat同时报告多个文件,请在命令行上将文件名传递给stat:
stat ana.h ana.o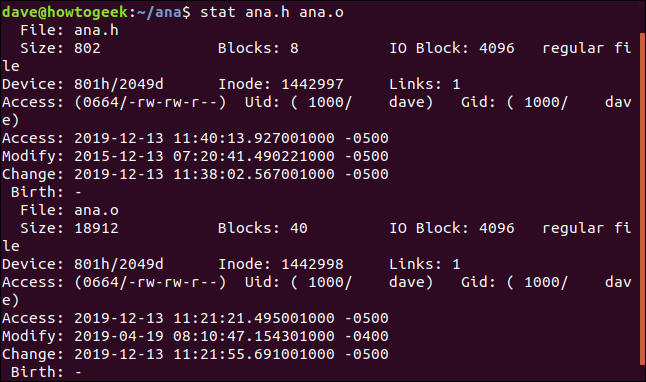
要对一组文件使用STAT,请使用模式匹配。问号“?”表示任意单个字符,星号“*”表示任意字符串。我们可以使用以下命令告诉统计信息报告任何具有单个字母扩展名的名为“ana”的文件:
stat ana.?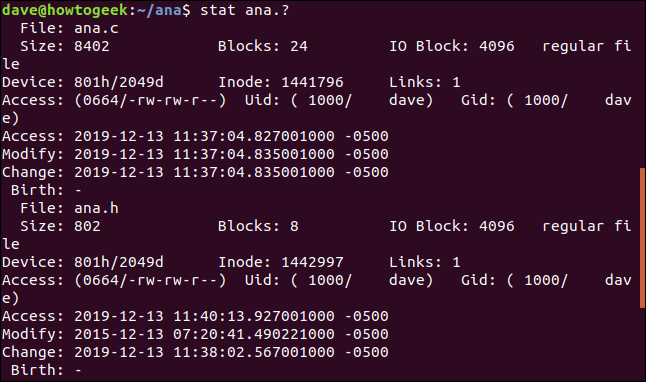
使用STAT报告文件系统
STAT可以报告文件系统的状态以及文件的状态。f(文件系统)选项告诉stat报告文件所在的文件系统。注意:我们还可以将“/”之类的目录传递给stat,而不是传递给文件名。
stat -f ana.c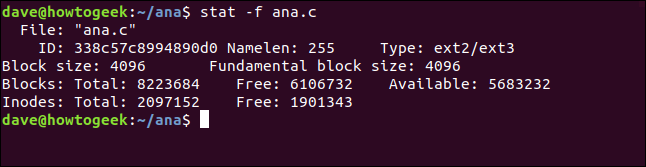
统计数据给我们的信息是:
文件:文件的名称。 ID:十六进制表示法中的文件系统ID。 Namelen:文件名允许的最大长度。 type:文件系统的类型。 块大小:请求读取请求以获得最佳数据传输率的数据量。 基本块大小:每个文件系统块的大小。
区块:
总数:文件系统中所有块的总计数。 FREE:文件系统中的空闲块数量。 Available:普通(非root)用户可用的空闲块数量。
信息节点:
Total:文件系统中信息节点的总数。 可用:文件系统中的空闲信息节点数。
取消引用符号链接
如果对实际是符号链接的文件使用STAT,它将报告该链接。如果希望stat报告链接所指向的文件,请使用-L(取消引用)选项。文件code.c是指向ana.c的符号链接。让我们看看不带-L选项的情况:
stat code.c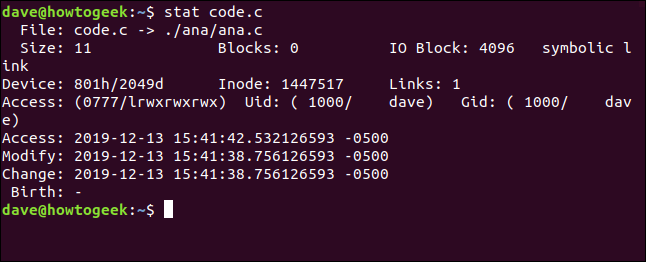
文件名显示code.c指向(->)ana.c。文件大小只有11个字节。有零个数据块专门用于存储此链接。文件类型作为符号链接列出。
显然,我们在这里看的不是实际的文件。让我们再做一次,并添加-L选项:
stat -L code.c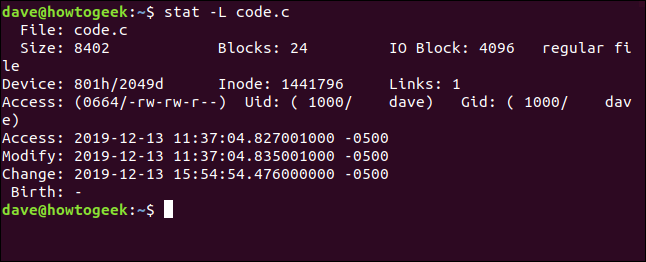
这现在显示了符号链接所指向的文件的文件详细信息。但是请注意,文件名仍然是以.code.c的形式给出的。这是链接的名称,而不是目标文件。这是因为这是我们在命令行上传递给stat的名称。
简明扼要的报告
t(简明)选项使stat提供精简的摘要:
stat -t ana.c
没有给出任何线索。为了理解它(直到您记住了字段序列),您需要将此输出交叉引用到完整的STAT输出。
自定义输出格式
从STAT获取不同数据集的更好方法是使用自定义格式。有一长串称为格式序列的令牌。这些元素中的每一个都表示一个数据元素。选择要包含在输出中的内容,并创建格式字符串。当我们调用stat并将格式字符串传递给它时,输出将只包括我们请求的数据元素。
文件和文件系统有不同的格式化序列集。文件列表如下:
%a:以八进制表示的访问权限。 %A:以人类可读形式(Rwx)表示的访问权限。 %b:分配的块数。 %B:每个块的大小(以字节为单位)。 %d:以十进制表示的设备号。 %D:十六进制的设备编号。 %f:十六进制的原始模式。 %F表示文件类型。 %g:所有者的组ID。 %G:所有者的组名。 %h:硬链接的数量。 %i:信息节点号。 %m:装载点。 %n:输入文件名。 %N:带引号的文件名,如果是符号链接,则带有取消引用的文件名。 %o:最佳I/O传输大小提示。 %s:总大小,以字节为单位。 %t:字符/块设备特殊文件的主要设备类型(十六进制)。 %T:字符/块设备特殊文件的十六进制次要设备类型。 %u:所有者的用户ID。 %U:所有者的用户名。 %w:文件的出生时间、人类可读时间或连字符“-”(如果未知)。 %W:文件出生时间,从纪元开始的秒数;如果未知,则为0。 %x:上次访问的时间,人类可读。 %X:上次访问的时间,自纪元以来的秒数。 %y:上次修改数据的时间,人类可读。 %Y:上次修改数据的时间,自纪元以来的秒数。 %z:上次状态更改的时间,人类可读。 %Z:上次状态更改的时间,自纪元以来的秒数。
“纪元”是Unix纪元,发生在1970-01-01 00:00:00+0000(UTC)。
对于文件系统,格式序列为:
%a:普通(非root)用户可用的空闲块数。 %b:文件系统中的数据块总数。 %c:文件系统中的信息节点总数。 %d:文件系统中的可用信息节点数。 %f:文件系统中的可用块数。 %i:十六进制的文件系统ID。 %l:文件名的最大长度。 %n:文件名。 %s:块大小(最佳写入大小)。 %S:文件系统块的大小(用于块计数)。 %t:以十六进制表示的文件系统类型。 %T:以人类可读形式表示的文件系统类型。
有两个选项可以接受格式序列字符串。它们是--format和--printf。它们之间的区别在于--printf解释C样式的转义序列,如newline\n和tab\t,并且它不会自动在其输出中添加换行符。
让我们创建一个格式字符串并将其传递给stat。要使用的格式序列为:文件名为%n,文件大小为%s,文件类型为%F。我们将在字符串的末尾添加\n转义序列,以确保在新行上处理每个文件。我们的格式字符串如下所示:
"File %n is %s bytes, and is a %F\n"我们将使用--printf选项将其传递给stat。我们将要求stat报告一个名为code.c的文件和一组与Ana.?匹配的文件。这是完整的命令。请注意--printf和格式字符串之间的等号“=”:
stat --printf="File %n is %s bytes, and is a %F\n" code.c ana/ana.?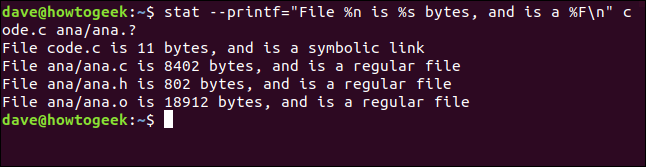
每个文件的报告都列在新行上,这是我们要求的。为我们提供了文件名、文件大小和文件类型。
自定义格式使您可以访问比标准STAT输出中包含的数据元素更多的数据元素。
细粒度控制
如您所见,提取您感兴趣的特定数据元素的范围很大。您可能也明白为什么我们推荐对更长、更复杂的咒语使用别名。